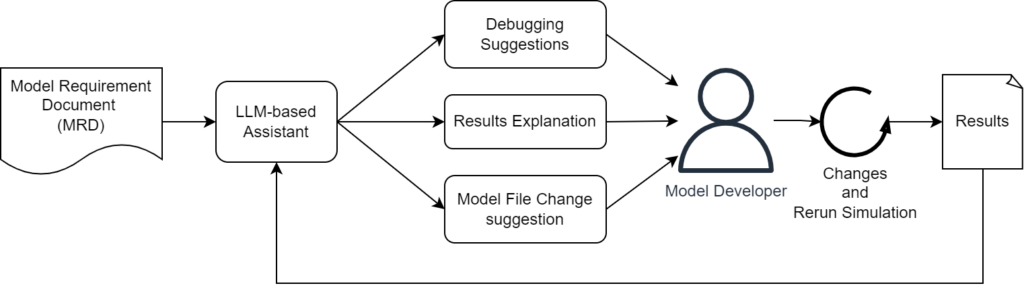
What contextual elements are most critical for enhancing the performance of large language models in building energy simulations?
– Wondering
Dear Wondering,
Large language models, or LLMs, have quickly become part of everyday technical conversations. At their core, they are neural network based models trained on massive text content to generate responses by learning semantic patterns. They are moving from novelty to practical implementations in building energy modeling (BEM) tools. In BEM, LLMs promise faster model creation, smarter debugging, and clearer explanation of results. Yet, fluency is not fidelity. For an LLM to become a reliable partner, it needs more than data. It needs context. That context determines whether the output reflects physical insight or misleading confidence.
Over multiple trials with BEM tools, six contextual elements consistently proved most critical for enhancing the performance of large language models:
- Relational Topology
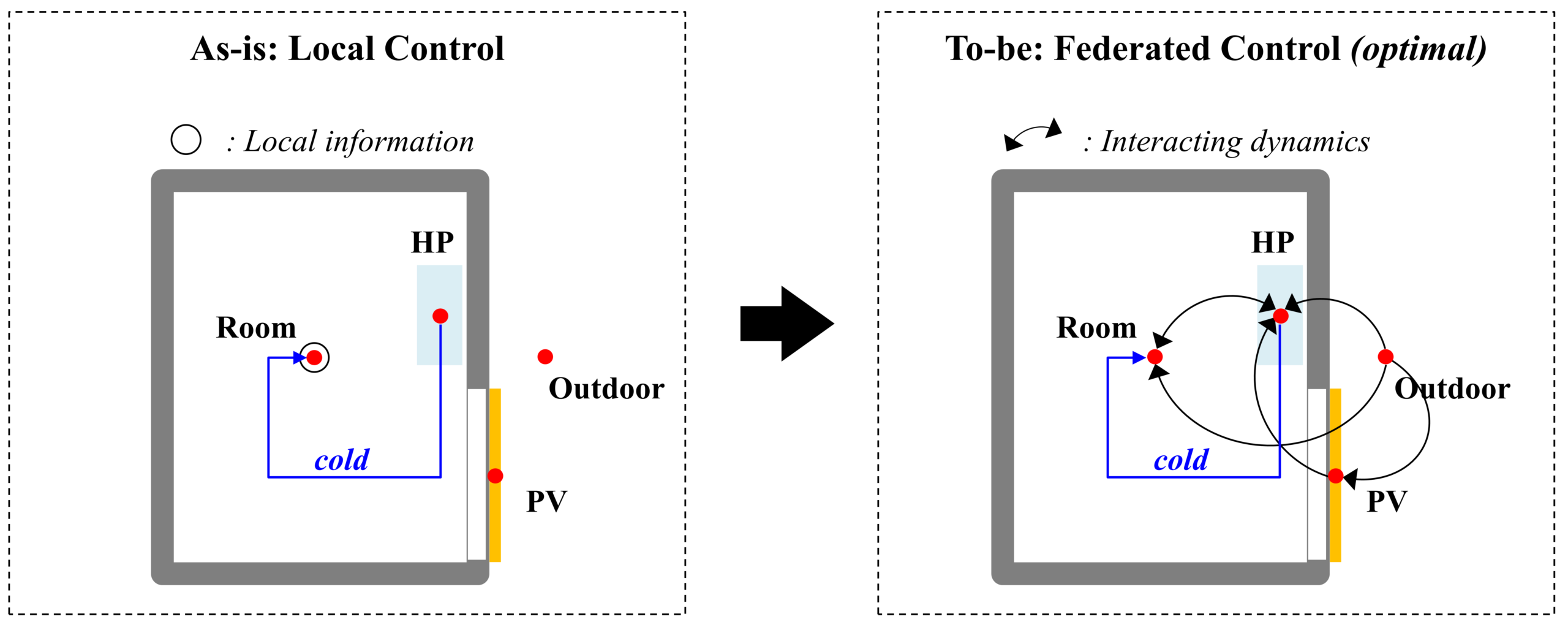
Buildings are not lists of components but systems of relationships. Knowing which air handler serves which zones and which pumps feed which chillers is as important as any individual parameter. Standards such as Project Haystack help make this explicit. When the model knows that AHU 01 serves VAV1-3 and those serve zones 101-103, it can generate a connected model that closes thermodynamically. Without topology, the LLM can debug a tree but not a forest.
- Structured component data
For LLMs, numbers are the bridge between text and physics. Structured component data allows quantitative reasoning grounded in real performance metrics. When information, such as “COP = 5.8”, is supplied, the model can make physics-consistent inferences. Vague descriptors like “efficient chiller” offer no such anchor. With structured inputs, the LLM can apply simple relations such as
to check plausibility and diagnose anomalies. For instance, if unmet cooling hours are high, the model can identify an undersized chiller from its capacity and COP and suggest resizing or staging changes.
- Design intent
Intent is often the most important part of the context. If an LLM is asked to debug a chiller plant or explain unexpected results, it will still optimize its reasoning unless the objective is explicit. Specify that the goal is to minimize site energy and it will push toward higher deltaT operation. Change the objective to minimizing grid impact during a demand response event and it will favor thermal storage and load shedding. The physics remain the same but the operational strategy changes. Without a clear purpose, the model’s reasoning can drift.
This idea is already familiar in software engineering. Developers using copilot/coding assistants often keep a requirements document in the repository so suggestions stay aligned with intent.
- Engine level context
Most of us at some point have been in the situation where we cannot fully explain the simulation results. We know the plant, but not always the simulation engine code.

Consider a case where zone temperature will not drop below 78 F, even though the cooling coil is correctly sized and the supply air temperature is 55 F. Without engine level context, the issue may be blamed on control sequencing. With access to simulation engine code, an LLM can identify that the solver is prioritizing humidity control and limiting coil output to prevent over dehumidification, an intentional solver decision. Engine level context allows the LLM to explain results by tracing back to code.
- Provenance and traceability
Trust in engineering depends on transparency. When an LLM modifies a model, it should record why the change was made. Supporting provenance means tracing each modification back to its source, such as a design submittal or revised assumption. The change ledger can be maintained either as an annotated section within the model file itself (e.g., comments in idf or Modelica code) or in a dedicated external log.
- Results as interactive context
Often the most time consuming part of modeling is explaining what the simulation produced and why. For reasoning, LLM must understand not just the values but how outputs relate to the system. A better approach is to provide structured glimpses of results: clear column names and a small sample of output. This gives the LLM enough context to generate or refine analysis. This iterative process, the model can narrow in on likely causes.

The road ahead
LLMs open a new way of working with building energy simulations, where interaction, explanation, and iteration become as important as execution. As these tools mature, they will shift effort away from manual investigation and toward higher level reasoning and design exploration. Human modelers remain in control, defining objectives and validating decisions, while LLMs amplify expertise through context aware reasoning. Used this way, LLMs have the potential to make building energy modeling more transparent, more accessible, and ultimately more impactful.

Kaustubh Pradeep Phalak, PhD
Lead Data Center Modeling Engineer, Trane Technologies